Zum Abschnitt springen
- Machine Learning und Big Data in der Fertigung
- Das Experiment: Erkennung von Anomalien in CNC-Daten
- Grafische Darstellung von Vorschubgeschwindigkeit, Spindeldrehzahl und produzierten Teilen über die Zeit
- Vorschubgeschwindigkeit vs. hergestellte Teile
- Geben Sie ein, Machine Learning: Ausreißer-Erkennungsalgorithmen zum Auffinden von Anomalien verwenden
- Zeitliche Darstellung der Ausreißer zur Aufdeckung der Ursachen
- Schlussfolgerungen
Machine Learning und Big Data in der Fertigung
Wir sprechen oft mit Herstellern, die daran interessiert sind, machine learning Algorithmen auf ihre Produktionsdaten anzuwenden.
Wie wir schon früher argumentiert haben, ist der Schlüssel zum Erfolg mit ML und KI eine solide Datenbasis. Deshalb sammelt die Plattform Tulip' Maschinenüberwachung die Daten, die Sie benötigen, um Ihre Abläufe wirklich zu verstehen.
Wenn es um Big Data-Analysen geht, ist es unser Ziel, ein Enabler zu sein. Tulip stellt Herstellern die Daten zur Verfügung, die sie benötigen, um die anspruchsvollsten Analysetechniken anzuwenden. Wir möchten, dass es für Data-Science-Teams und Ingenieure ganz einfach ist, in ihren Werkstätten Daten zu sammeln und aus Tulip zu extrahieren, damit sie ein neues Niveau an Produktivität und Qualität erreichen können.
In diesem Beitrag zeigen wir Ihnen, wie Sie einfache, leistungsstarke Data Science-Techniken auf die Daten anwenden können, die Sie mit Tulip sammeln.
[Sehen Sie sich unser On-Demand-Webinar an] Wie führende Hersteller die Fabriken der Zukunft bauen →
Das Experiment: Erkennung von Anomalien in CNC-Daten
Um zu zeigen, wie Tulip Data-Science-Initiativen unterstützen kann, haben wir ein kurzes Experiment mit Daten durchgeführt, die von einem Tulip Kunden (hier anonymisiert) generiert wurden.
Für die Zwecke dieses Experiments haben wir einen Datensatz ausgewählt, der von einem Kunden mit Tulip für Maschinenüberwachung gesammelt wurde. Wir haben diesen Datensatz aus mehreren Gründen ausgewählt.
Erstens ist der Datensatz groß genug, um machine learning Modelle richtig zu trainieren. Wir haben Daten aus einem 24-Stunden-Fenster entnommen, und der Datensatz umfasste mehrere hunderttausend Zeilen. Das ist genug für die meisten Klassifizierungs-, Clustering- und Anomalieerkennungsalgorithmen, um zuverlässige Ergebnisse zu erzielen.
Zweitens konzentrierte sich der Datensatz auf die Maschinenüberwachung Informationen, die für Hersteller am wichtigsten sind. Aus diesem Datensatz konnten wir kritische KPIs wie Vorschubgeschwindigkeit, Spindeldrehzahl und Durchsatz grafisch darstellen - die Grundlagen, die Sie für die Optimierung von Programmen und die Berechnung von Gesamtanlageneffektivität (OEE) benötigen. Die Daten enthielten genügend Parameter, um eine Analyse durchzuführen, die für die Aktivitäten in der Fertigung relevant ist und mit den Arten von Fertigungsanalysen übereinstimmt, die unsere Kunden tagtäglich verwenden.
Um die Analyse durchzuführen, haben wir beliebte Python-Bibliotheken wie PANDAS und Sci Kit Learn in Jupyter Notebook verwendet. Für Data-Science-Teams ist dieselbe Analyse in der von Ihnen bevorzugten Sprache möglich und kann in Microsoft Azure 's Data Studio, AWS's SageMaker oder jeder anderen Analyseumgebung durchgeführt werden, die Sie in Ihrem Betrieb verwenden.
Abrufen der Daten
Das Abrufen der Daten von Tulip war einfach. Die Daten waren in Tabellen ohne Code gespeichert, die genau die Parameter enthielten, die wir benötigten.
Die ersten Schritte waren so einfach wie das Herunterladen einer CSV-Datei, das Importieren in unser Notebook und das Erstellen eines Datenrahmens. Das dauerte 5 Minuten und zwei Zeilen Code.
Wie sieht eine KI-gestützte Qualitätsprüfung mit Tulip aus?
Integrieren Sie eine Machine Learning-gestützte Fehlererkennung in Ihre Arbeitsabläufe mit handelsüblichen Kameras und No-Code-Konfiguration.
Grafische Darstellung von Vorschubgeschwindigkeit, Spindeldrehzahl und produzierten Teilen über die Zeit
Der nächste Schritt nach der Organisation der .csv-Datei in Datenrahmen war die Erstellung von Diagrammen zur Visualisierung der Vorgänge in der Werkstatt.
Zu Beginn haben wir ein Diagramm erstellt, in dem wir drei wichtige Daten von Produktionsdaten miteinander verglichen haben: Spindeldrehzahl, Vorschubgeschwindigkeit und produzierte Teile über die Zeit.
Diese drei Metriken sind entscheidend für die Optimierung der Produktion und die Gewährleistung der langfristigen Gesundheit der Anlagen. Da zwei identische Maschinen, die das gleiche Programm in der gleichen Fabrik ausführen, sehr unterschiedliche Gesamtanlageneffektivität (OEE) haben können, ist es wichtig, genau zu messen, was während eines Produktionslaufs passiert.

Dieses Diagramm gibt einen guten Überblick über die Produktion in diesem 24-Stunden-Fenster (die Linien sind ziemlich zackig, weil wir eine relativ niedrige Abtastrate von 20 Minuten verwendet haben; schnellere Abtastraten führten zu verrauschten Diagrammen). Im Großen und Ganzen zeigt sich, was Sie von Maschinendaten erwarten würden. An fast allen Punkten gibt es eine starke Korrelation zwischen Spindeldrehzahl und Vorschubgeschwindigkeit, zwischen Spindeldrehzahl:Vorschubgeschwindigkeit und produzierten Teilen.
Es gibt jedoch auch einige Punkte, bei denen die Vorschubgeschwindigkeit umgekehrt proportional zu den produzierten Teilen ist, während die Spindeldrehzahl gleich bleibt. Es gibt sogar zwei Fälle, in denen die Spindeldrehzahl und die Vorschubgeschwindigkeit gleich Null sind, aber trotzdem Teile produziert werden.
Letztlich wirft diese Grafik mehr Fragen auf, als sie beantwortet. Aber sie erfüllt ihren Zweck. Sie zeigt Bereiche auf, die weiter untersucht werden sollten, und ermöglicht es, tiefer in die Daten einzudringen.
Vorschubgeschwindigkeit vs. hergestellte Teile
Das vorherige Diagramm machte uns darauf aufmerksam, dass die Vorschubgeschwindigkeit nicht immer mit den produzierten Teilen korreliert. Der nächste Schritt bestand also darin, die produzierten Teile gegen die Vorschubgeschwindigkeit aufzurechnen, um diese Beziehung besser zu verstehen.

In diesem Diagramm können wir sehen, dass die Anzahl der gefertigten Teile sprunghaft ansteigt, wenn die Vorschubgeschwindigkeit 1400 erreicht. Die Anzahl der gefertigten Teile nimmt weiter zu, wenn sich die Vorschubgeschwindigkeit 1600 nähert.
Was diese Grafik visuell erkennen lässt (dass sich die hergestellten Teile bei einer Vorschubgeschwindigkeit von etwa 1600 zwischen 5 und 10 zu häufen scheinen), könnte durch weitere Analysen bestätigt werden. (Oder, wenn Sie für dieses Programm Daten verwenden, die im Laufe vieler Tage gesammelt wurden, könnten Sie lineare Regressionen verwenden, um die bei einer bestimmten Vorschubgeschwindigkeit produzierten Teile vorherzusagen, um eine bessere Bilanzierung zu erreichen).
Nichts in dieser Grafik ist überraschend. Und das ist gut so. Das bedeutet jedoch, dass wir noch weiter in die Tiefe gehen müssen, um besser zu verstehen, was in den Betrieben passiert.
Geben Sie ein, Machine Learning: Ausreißer-Erkennungsalgorithmen zum Auffinden von Anomalien verwenden
Der nächste Schritt bestand darin, die Spindeldrehzahl gegen die Vorschubgeschwindigkeit aufzuzeichnen. Auf diese Weise konnten wir genau feststellen, welche Einstellungen mit dem höchsten Durchsatz korreliert sind.

Während des gesamten Produktionstages korrelieren hohe Spindeldrehzahlen stark mit hohen Vorschubgeschwindigkeiten. Auch dies ist zu erwarten.
Wir haben jedoch mehrere Punkte festgestellt, die nicht diesen Mustern entsprachen. Die Frage, die wir uns an dieser Stelle stellten, lautete: "Inwieweit gibt es statistische Ausreißer in diesem Diagramm?"
Die Antwort auf diese Frage ist aus zwei Gründen wichtig. Zum einen könnten diese Ausreißer auf Verhaltensweisen oder Prozesse in der Fertigung hinweisen, die sich direkt auf die Produktion auswirken. Das Auffinden und Verstehen dieser Datenpunkte kann sich also direkt in einer höheren Produktivität niederschlagen. Zweitens können Ausreißer die Leistung vieler machine learning Algorithmen beeinträchtigen. Daher ist die Entscheidung, ob wir diese Punkte aus unserer Analyse ausschließen müssen, von entscheidender Bedeutung, um genaue Erkenntnisse zu gewinnen.
Um festzustellen, ob unser Datensatz Ausreißer enthält, haben wir eine Methode namens Isolation Forest verwendet(mehr über diese Technik können Sie hier lesen).
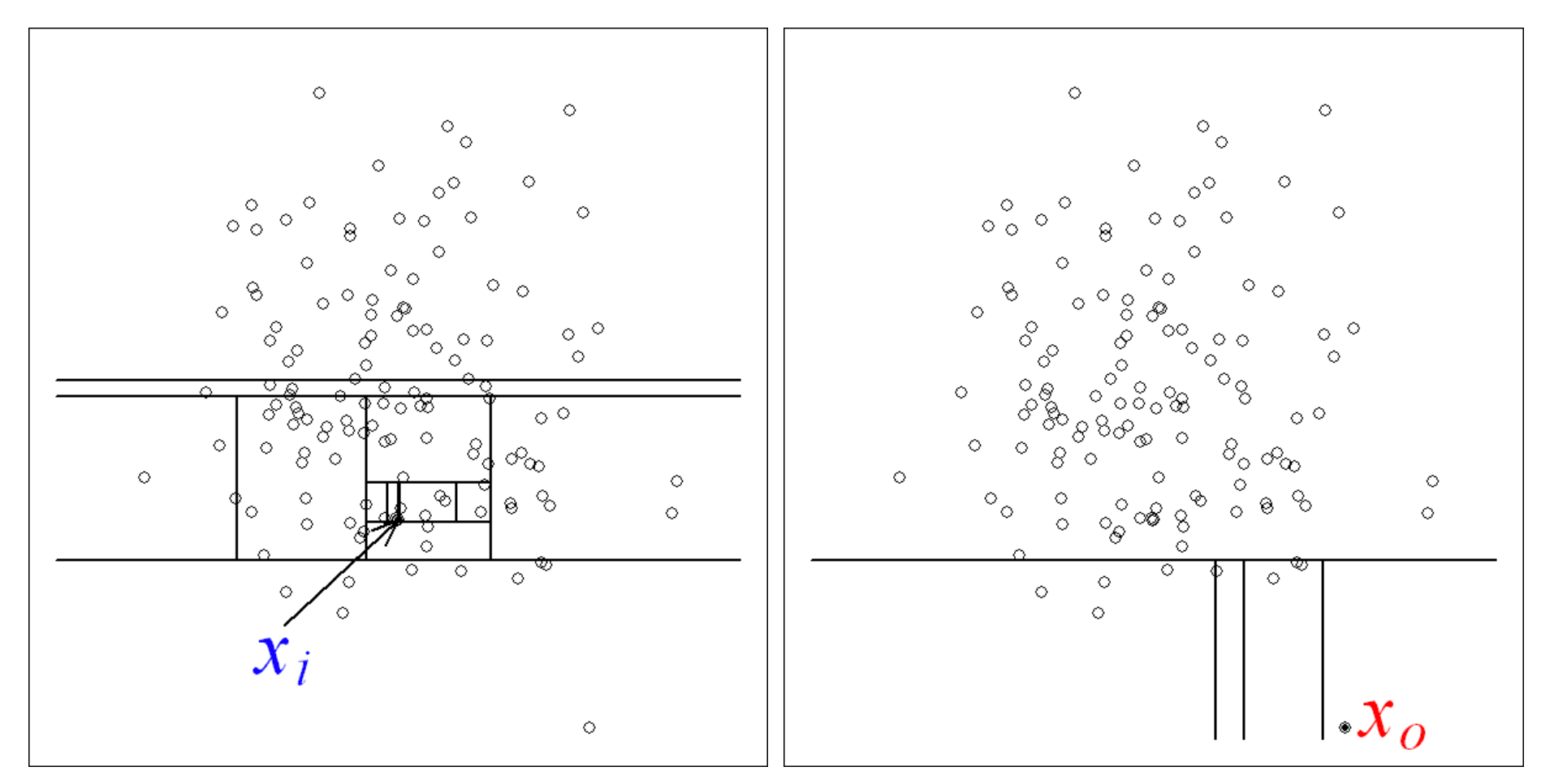
Der Isolation Forest hat 5 Datenpunkte gefunden, die er als Ausreißer betrachtet.
Dadurch erhalten wir nicht nur einen saubereren Datensatz, sondern können auch eine entscheidende Frage stellen: Was geschah mit diesen Maschinen zu diesen Zeitpunkten?
Zeitliche Darstellung der Ausreißer zur Aufdeckung der Ursachen
Der letzte Schritt dieses Experiments bestand darin, unsere Anomalien auf unser anfängliches Diagramm des Produktionstages zurück zu übertragen.
Schauen wir uns zunächst die drei Linien an, die kurz nach 03:00 Uhr auftreten. Wenn wir dies mit unserem ursprünglichen Diagramm vergleichen (Vorschub, Spindeldrehzahl, produzierte Teile über die Zeit), sehen wir, dass alle drei Ausreißer mit einem steilen Abfall aller drei Messgrößen zusammenfallen.
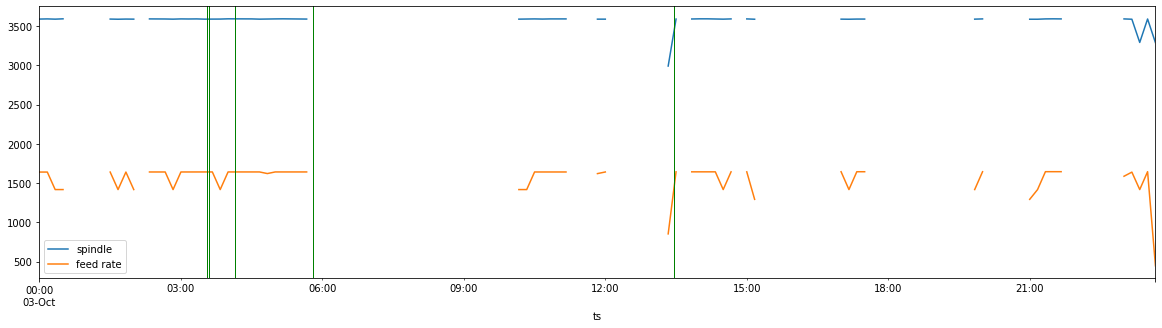
Die Frage lautet: Was ist dann passiert? Wenn wir diese Ereignisse auf diese Weise grafisch darstellen, können wir fundiertere Fragen stellen. Wer war der Bediener? Welches Programm wurde ausgeführt? Wie waren die Bedingungen in der Fabrik? Wer war der Schichtleiter? Wurde eine Umrüstung korrekt ausgeführt? War das richtige Werkzeug verfügbar? Gab es ein mechanisches Problem?
Dies sind nur einige der vielen Fragen, die Hersteller täglich beantworten müssen, um ihren Betrieb so profitabel wie möglich zu gestalten.
Außerdem müssen Sie mit Tulip's Maschinenüberwachung Ihre Analyse nicht auf diese drei Variablen beschränken. Mit Tulip können Sie auch andere Parameter verfolgen, die diesen allgemeinen Parametern zusätzliche Nuancen und Perspektiven verleihen.
Schlussfolgerungen
Diese Analyse ist vereinfacht. Es gibt keinen Grund, etwas anderes zu behaupten.
Wenn Sie jedoch einfache machine learning Analysen Ihrer Maschinenüberwachung Daten durchführen, können Sie feststellen, welche Fragen zu einem bestimmten Zeitpunkt am besten zu stellen sind.
Dies ist der wahre Wert der Erweiterung von Maschinenüberwachung mit machine learning. Die Algorithmen können Ihnen helfen, Ordnung in riesigen Datensätzen zu finden. Aber letztlich geben sie Ingenieuren die Möglichkeit, schwierige Fertigungsprobleme in kürzerer Zeit und mit größerer Sicherheit als je zuvor zu isolieren und zu lösen.
Zum Schluss möchten wir noch einen Punkt hervorheben.
Wir waren in der Lage, diese Analyse in wenigen Stunden zu erstellen. Da Tulip tables die Daten in einer zugänglichen Form sammelt und organisiert, mussten wir keine Tabellen mit SQL erstellen und auch nicht viel Zeit mit der mühsamen Arbeit des Feature Engineering verbringen.
Für diese Art der Analyse braucht man weder einen Master-Abschluss in Datenwissenschaft noch teure Software. Einer unserer Ingenieure hat sie in wenigen Stunden mit Hilfe von branchenüblichen, öffentlich verfügbaren Analysebibliotheken zusammengestellt. Ein Team aus Geschäftsleuten, Analysten und Datenwissenschaftlern, das mit maßgeschneiderten Datensätzen arbeitet, die von Tulip gesammelt wurden, könnte in der gleichen Zeit viel mehr erreichen.
Es ging uns hier nicht darum, eine endgültige Analyse zu erstellen, sondern zu zeigen, wie einfach es ist, Erkenntnisse zu gewinnen, die einen Unterschied machen.
Nehmen Sie Kontakt auf, um noch heute mit Maschinenüberwachung zu beginnen..