Aller à la section
- Apprentissage machine et Big Data dans l'industrie manufacturière
- L'expérience : Détection d'anomalies dans les données de la CNC
- Graphique de la vitesse d'avance, de la vitesse de rotation de la broche et des pièces produites au fil du temps
- Vitesse d'alimentation en fonction des pièces produites
- Entrez, Apprentissage machine: Utilisation d'algorithmes de détection des valeurs aberrantes pour trouver des anomalies
- La représentation graphique des valeurs aberrantes à temps pour révéler les causes profondes
- Conclusions
Apprentissage machine et Big Data dans l'industrie manufacturière
Nous discutons souvent avec des fabricants qui souhaitent appliquer les algorithmes de Apprentissage machine à leurs données de fabrication.
C'est pourquoi la plateforme Tulip's Suivi machine recueille les données dont vous avez besoin pour comprendre véritablement vos opérations.
Lorsqu'il s'agit d'analyse de big data, notre objectif est d'être un facilitateur. Tulip fournit aux fabricants les données dont ils ont besoin pour appliquer les techniques d'analyse les plus sophistiquées possibles. Nous voulons faciliter la tâche des équipes de science des données et des ingénieurs qui collectent des données dans leurs ateliers et les extraient de Tulip afin qu'ils puissent atteindre de nouveaux niveaux de productivité et de qualité.
Dans cet article, nous allons vous montrer comment vous pouvez appliquer des techniques simples et puissantes de science des données aux données que vous collectez avec Tulip.
L'expérience : Détection d'anomalies dans les données de la CNC
Afin de montrer comment Tulip peut renforcer les initiatives de science des données, nous avons mené une expérience rapide en utilisant les données générées par un client de Tulip (anonymisées ici).
Pour les besoins de cette expérience, nous avons sélectionné un ensemble de données collectées par un client utilisant Tulip pour Suivi machine. Nous avons choisi cet ensemble de données pour plusieurs raisons.
Tout d'abord, l'ensemble de données est suffisamment important pour entraîner correctement les modèles Apprentissage machine . Nous avons extrait les données d'une fenêtre de 24 heures et l'ensemble de données comptait plusieurs centaines de milliers de lignes. C'est suffisant pour que la plupart des algorithmes de classification, de regroupement et de détection d'anomalies produisent des résultats fiables.
Deuxièmement, l'ensemble des données s'est concentré sur les informations Suivi machine qui intéressent le plus les fabricants. À partir de cet ensemble de données, nous avons été en mesure de représenter graphiquement des indicateurs clés de performance essentiels tels que la vitesse d'avance, la vitesse de la broche et le débit - les éléments de base dont vous avez besoin pour optimiser les programmes et calculer TRS. Les données comportaient suffisamment de paramètres pour permettre une analyse pertinente de l'activité de l'atelier, et cohérente avec les types d'analyses de fabrication que nos clients utilisent tous les jours.
Pour effectuer l'analyse, nous avons utilisé des bibliothèques python populaires telles que PANDAS et Sci Kit Learn dans Jupyter Notebook. Pour les équipes de science des données, cette même analyse est possible dans le langage que vous préférez et peut être réalisée dans Microsoft Azure 's Data Studio, AWS's SageMaker, ou tout autre environnement d'analyse que vous utilisez dans vos opérations.
Extraction des données
Il a été facile d'extraire les données de Tulip . Les données étaient stockées dans des tableaux sans code qui contenaient les paramètres exacts dont nous avions besoin.
Pour commencer, il a suffi de télécharger un fichier CSV, de l'importer dans notre notebook et de créer un cadre de données. Cela a pris 5 minutes et deux lignes de code.
À quoi ressemble une inspection de qualité basée sur l'IA avec Tulip?
Intégrez la détection de défaut par Machine Learning dans les séquences de travail de vos opérateurs avec des caméras disponibles dans le commerce et une configuration No-Code.
Graphique de la vitesse d'avance, de la vitesse de rotation de la broche et des pièces produites au fil du temps
Après avoir organisé le fichier .csv en cadres de données, l'étape suivante a consisté à créer des graphiques pour visualiser ce qui se passait dans l'atelier.
Pour commencer, nous avons créé un graphique mettant en correspondance trois éléments critiques du site données de production : la vitesse de la broche, la vitesse d'avance et les pièces produites au fil du temps.
Ces trois mesures sont essentielles pour optimiser la production et garantir la santé des actifs à long terme. Étant donné que deux machines identiques exécutant le même programme dans la même usine peuvent présenter des différences significatives TRS, il est important de mesurer exactement ce qui se passe au cours d'un cycle de production.

Ce graphique donne un bon aperçu de la production pendant cette fenêtre de 24 heures (les lignes sont assez irrégulières car nous avons utilisé un taux d'échantillonnage relativement faible de 20 minutes ; des taux d'échantillonnage plus élevés produisent des graphiques bruités). Dans l'ensemble, il montre ce que l'on peut attendre des données relatives aux machines. À presque tous les points, il y a une forte corrélation entre la vitesse de la broche et la vitesse d'avance, entre la vitesse de la broche et la vitesse d'avance et les pièces produites.
Mais il y a aussi des cas où l'avance est inversement proportionnelle aux pièces produites alors que la vitesse de la broche reste la même. Il y a même deux cas où la vitesse de la broche et l'avance sont nulles, mais où des pièces sont produites.
En fin de compte, ce graphique pose plus de questions qu'il n'apporte de réponses. Mais il fait son travail. Il suggère des domaines à approfondir et permet d'approfondir les données.
Vitesse d'alimentation en fonction des pièces produites
Le graphique précédent nous a alertés sur le fait que l'avance n'était pas toujours corrélée avec les pièces produites. L'étape suivante consistait donc à représenter graphiquement les pièces produites en fonction de l'avance afin de mieux comprendre cette relation.

Sur ce graphique, nous pouvons voir que le nombre de pièces fabriquées commence à augmenter précipitamment lorsque l'avance atteint 1400. Le nombre de pièces fabriquées continue d'augmenter lorsque l'avance approche 1600.
Ce que ce graphique révèle visuellement (que les pièces produites semblent se situer entre 5 et 10 à une vitesse d'avance d'environ 1600) pourrait être confirmé par une analyse plus approfondie. (Ou, si vous utilisez pour ce programme des données collectées sur plusieurs jours, vous pourriez utiliser des régressions linéaires pour prédire les pièces produites à une vitesse d'avance donnée afin d'améliorer l'équilibrage des lignes).
Rien dans ce graphique n'est surprenant. C'est une bonne chose. Cela signifie toutefois que nous devons approfondir la question pour mieux comprendre ce qui se passe dans l'atelier.
Entrez, Apprentissage machine: Utilisation d'algorithmes de détection des valeurs aberrantes pour trouver des anomalies
L'étape suivante a consisté à représenter graphiquement la vitesse de la broche en fonction de la vitesse d'avance. Cela nous a permis de comprendre exactement quels paramètres sont corrélés avec le débit le plus élevé.

Sur l'ensemble de la journée de production, les vitesses de broche élevées sont fortement corrélées avec les vitesses d'avance élevées. Là encore, c'est normal.
Mais nous avons remarqué plusieurs points qui ne correspondaient pas à ces modèles. La question que nous nous sommes posée à ce stade est la suivante : "Dans quelle mesure ce graphique présente-t-il des valeurs statistiques aberrantes ?"
La réponse à cette question est importante pour deux raisons. D'une part, ces valeurs aberrantes peuvent révéler des comportements ou des processus dans l'atelier qui ont un impact direct sur la production. En d'autres termes, la localisation et la compréhension de ces points de données peuvent se traduire directement par une augmentation de la productivité. Deuxièmement, les valeurs aberrantes peuvent nuire aux performances de nombreux algorithmes Apprentissage machine . Il est donc essentiel de déterminer si nous devons exclure ces points de notre analyse pour obtenir des informations précises.
Pour déterminer si notre ensemble de données comprend des valeurs aberrantes, nous avons utilisé une méthode appelée forêt d'isolement(vous pouvez en savoir plus sur cette technique ici).
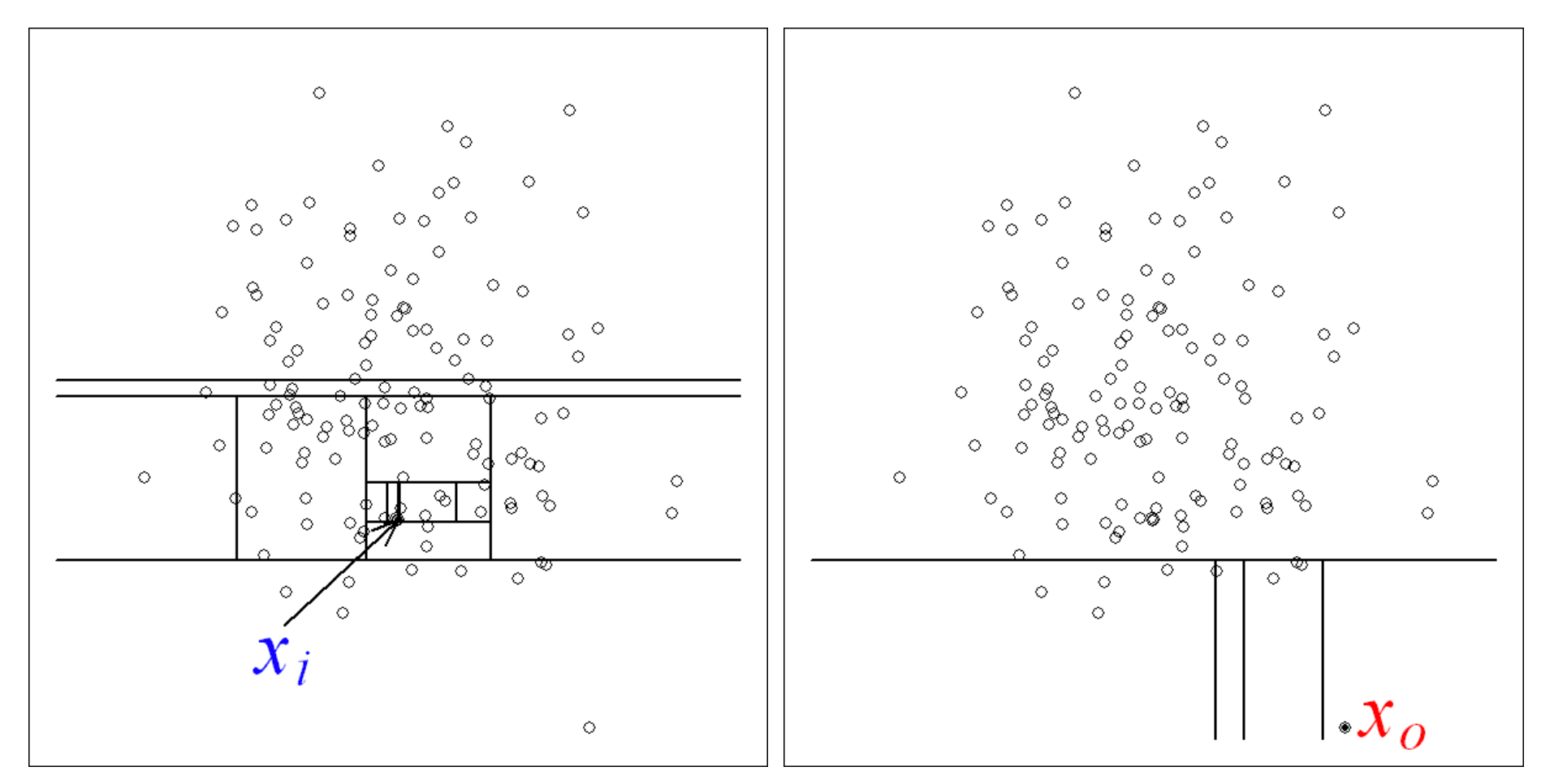
La forêt d'isolation a localisé 5 points de données qu'elle a considérés comme aberrants.
Cela nous permet non seulement de disposer d'un ensemble de données plus nettes, mais aussi de poser une question essentielle : que se passait-il avec ces machines à ces moments-là ?
La représentation graphique des valeurs aberrantes à temps pour révéler les causes profondes
L'étape finale de cette expérience a consisté à reporter nos anomalies sur notre graphique initial de la journée de production.
Examinons d'abord les trois lignes qui apparaissent juste après 03:00. Si nous les comparons à notre graphique initial (vitesse d'avance, vitesse de broche, pièces produites au cours du temps), nous constatons que ces trois valeurs aberrantes coïncident avec une chute brutale de ces trois paramètres.
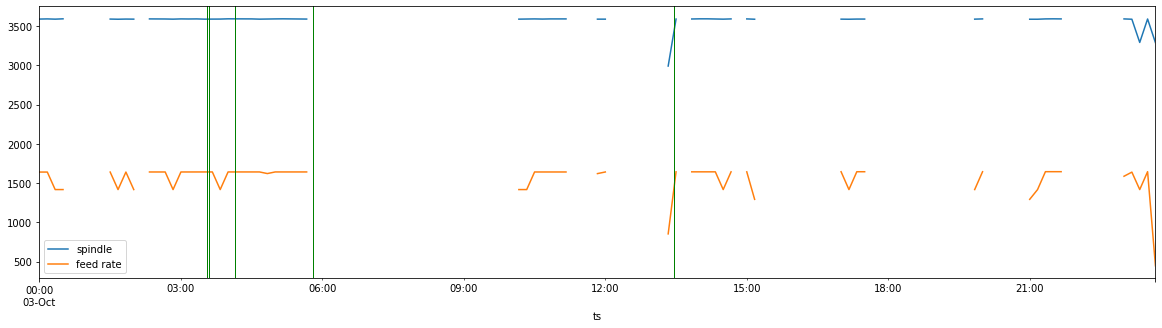
La question qui se pose alors est la suivante : que s'est-il passé alors ? Il est important de noter que la représentation graphique de ces événements nous permet de poser des questions plus précises. Qui était l'opérateur ? Quel programme était en cours d'exécution ? Quelles étaient les conditions dans l'usine ? Qui était le chef d'équipe ? Un changement a-t-il été effectué correctement ? Le bon outil était-il disponible ? Y a-t-il eu un problème mécanique ?
Ce sont là quelques-unes des nombreuses questions auxquelles les fabricants doivent répondre quotidiennement pour rendre leurs activités aussi rentables que possible.
De plus, avec Tulip's Suivi machine, vous ne devez pas limiter votre analyse à ces trois variables. Avec Tulip, vous pouvez suivre d'autres paramètres qui ajouteront de la nuance et de la perspective à ces paramètres communs.
Conclusions
Cette analyse est simpliste. Il n'y a aucune raison de prétendre le contraire.
Mais en effectuant de simples analyses Apprentissage machine sur vos données Suivi machine , vous déterminez quelles sont les meilleures questions à poser à un moment donné.
C'est là que réside la véritable valeur de l'ajout de Suivi machine à Apprentissage machine. Les algorithmes peuvent vous aider à trouver de l'ordre dans des ensembles de données massives. Mais en fin de compte, ils donnent aux ingénieurs la possibilité d'isoler et de résoudre des problèmes de fabrication difficiles en moins de temps et avec plus de certitude que jamais auparavant.
Pour conclure, nous aimerions insister sur un point.
Nous avons pu réaliser cette analyse en quelques heures. Comme les tables Tulip collectent et organisent les données de manière accessible, il n'a pas été nécessaire de créer des tables avec SQL, et nous n'avons pas eu besoin de passer beaucoup de temps à faire le travail minutieux de l'ingénierie des fonctionnalités.
Ce type d'analyse ne nécessite pas de master en science des données ni de logiciel coûteux. L'un de nos ingénieurs l'a réalisée en quelques heures à l'aide de bibliothèques d'analyse standard et accessibles au public. Une équipe d'analystes commerciaux et de scientifiques des données travaillant avec des ensembles de données personnalisés collectés par Tulip pourrait aller beaucoup plus loin dans le même laps de temps.
Notre intention n'était pas de produire une analyse définitive, mais plutôt de montrer à quel point il est facile de créer des informations qui font la différence.