Saltar a la sección
- Aprendizaje automático y Big Data en la fabricación
- El experimento: Detección de anomalías en datos CNC
- Gráfico de la velocidad de avance, la velocidad del husillo y las piezas producidas a lo largo del tiempo
- Velocidad de avance frente a piezas fabricadas
- Entre, Aprendizaje automático: Utilizar algoritmos de detección de valores atípicos para encontrar anomalías
- Graficar los valores atípicos en el tiempo para revelar las causas profundas
- Conclusiones
Aprendizaje automático y Big Data en la fabricación
A menudo hablamos con fabricantes interesados en aplicar algoritmos de aprendizaje automático a sus datos de fabricación.
Como hemos argumentado antes, la clave del éxito con ML e IA son unos datos sólidos, por lo que la plataforma de supervisión de máquinas de Tuliprecopila los datos que necesita para comprender realmente sus operaciones.
Cuando se trata de análisis de big data, nuestro objetivo es ser un facilitador. Tulip proporciona a los fabricantes los datos que necesitan para aplicar las técnicas de análisis más sofisticadas posibles. Queremos que sea trivial para los equipos de ciencia de datos y los ingenieros recopilar en sus talleres y extraer datos de Tulip para que puedan desbloquear nuevos niveles de productividad y calidad.
En este post, le demostraremos cómo puede aplicar técnicas sencillas y potentes de ciencia de datos a los datos que recopile con Tulip.
El experimento: Detección de anomalías en datos CNC
Para mostrar cómo Tulip puede potenciar las iniciativas de la ciencia de datos, realizamos un rápido experimento utilizando datos generados por un cliente de Tulip (anonimizados aquí).
A efectos de este experimento, seleccionamos un conjunto de datos recogidos por un cliente que utiliza Tulip para la supervisión de máquinas. Elegimos este conjunto de datos por varias razones.
En primer lugar, el conjunto de datos es lo suficientemente grande como para entrenar adecuadamente los modelos de aprendizaje automático. Extrajimos datos de una ventana de 24 horas, y el conjunto de datos llegó a los cientos de miles de filas. Esto es suficiente para que la mayoría de los algoritmos de clasificación, agrupación y detección de anomalías produzcan resultados fiables.
En segundo lugar, el conjunto de datos se centró en la información de supervisión de la máquina que más interesa a los fabricantes. A partir de este conjunto de datos pudimos trazar gráficos de KPI críticos como la velocidad de avance, la velocidad del husillo y el rendimiento, los datos básicos que se necesitan para optimizar los programas y calcular la OEE. Los datos incluían suficientes parámetros para realizar un análisis relevante para la actividad en el taller, y coherente con los tipos de análisis de fabricación que vemos que nuestros clientes utilizan a diario.
Para realizar el análisis, utilizamos bibliotecas populares de python como PANDAS y Sci Kit Learn en Jupyter Notebook. Para los equipos de ciencia de datos, este mismo análisis es posible en cualquier lenguaje que prefiera, y puede realizarse en Microsoft Azure 's Data Studio, AWS's SageMaker, o cualquier entorno de análisis que utilice en sus operaciones.
Obtención de datos
Sacar los datos de Tulip fue fácil. Los datos estaban almacenados en tablas sin código que contenían los parámetros exactos que necesitábamos.
Empezar fue tan sencillo como descargar un CSV, importarlo a nuestro cuaderno y crear un marco de datos. Nos llevó 5 minutos y dos líneas de código.
¿Qué aspecto tiene la inspección de calidad posibilitada por la IA con Tulip?
Integre la detección de defectos con tecnología de aprendizaje automático en los flujos de trabajo de los operadores mediante cámaras listas para usar y configuración sin programación.
Gráfico de la velocidad de avance, la velocidad del husillo y las piezas producidas a lo largo del tiempo
El siguiente paso tras organizar el archivo .csv en marcos de datos fue crear gráficos para visualizar lo que ocurría en el taller.
Para empezar, creamos un gráfico en el que se comparaban tres datos críticos de producción: la velocidad del husillo, la velocidad de avance y las piezas producidas a lo largo del tiempo.
Estas tres métricas son fundamentales para optimizar la producción y garantizar la salud de los activos a largo plazo. Dado que dos máquinas idénticas que ejecutan el mismo programa en la misma fábrica pueden tener una OEE significativamente diferente, es importante medir exactamente lo que ocurre durante una tirada de producción.

Este gráfico proporciona una buena visión general de la producción durante esta ventana de 24 horas (las líneas son bastante irregulares porque utilizamos una frecuencia de muestreo relativamente baja de 20 minutos; las frecuencias de muestreo más rápidas produjeron gráficos con ruido). En su mayor parte, muestra lo que cabría esperar de los datos de la máquina. En casi todos los puntos, hay una fuerte correlación entre la velocidad del husillo y la velocidad de avance, entre la velocidad del husillo:velocidad de avance y las piezas producidas.
Sin embargo, también hay algunos puntos en los que la velocidad de avance está inversamente relacionada con las piezas producidas mientras que la velocidad del husillo se mantiene igual. Incluso hay dos casos en los que la velocidad del husillo y la velocidad de avance son cero y, sin embargo, se siguen produciendo piezas.
En última instancia, este gráfico plantea más preguntas de las que responde. Pero hace su trabajo. Indica áreas para una investigación más profunda y permite profundizar en los datos.
Velocidad de avance frente a piezas fabricadas
El gráfico anterior nos alertó del hecho de que la velocidad de avance no siempre estaba correlacionada con las piezas producidas. El siguiente paso fue, por tanto, hacer un gráfico de las piezas fabricadas frente a la velocidad de avance para comprender mejor esa relación.

En este gráfico, podemos ver que las piezas fabricadas comienzan a aumentar precipitadamente cuando el avance alcanza los 1400. El número de piezas fabricadas sigue aumentando a medida que el avance se acerca a 1600.
Lo que este gráfico revela visualmente (que las piezas fabricadas parecen agruparse entre 5 y 10 a una velocidad de avance de aproximadamente 1600, podría confirmarse mediante un análisis más detallado. (O, si utilizara datos para este programa recogidos a lo largo de muchos días, podría utilizar regresiones lineales para predecir las piezas producidas a una velocidad de avance determinada para un mejor equilibrado de la línea).
Nada en este gráfico es sorprendente. Lo cual es bueno. Eso significa, sin embargo, que tenemos que profundizar más para entender mejor lo que está sucediendo en el taller.
Entre, Aprendizaje automático: Utilizar algoritmos de detección de valores atípicos para encontrar anomalías
El siguiente paso fue hacer un gráfico de la velocidad del husillo frente a la velocidad de avance. Hacerlo nos permitió comprender exactamente qué ajustes se correlacionan con el mayor rendimiento.

A lo largo de la jornada de producción, las altas velocidades de los husillos están muy correlacionadas con las altas velocidades de avance. De nuevo, esto es de esperar.
Pero observamos varios puntos que no se ajustaban a estos patrones. La pregunta que nos planteamos en este punto es: "¿hasta qué punto hay valores estadísticos atípicos en este gráfico?".
La respuesta a esta pregunta es importante por dos razones. Por un lado, esos valores atípicos podrían revelar comportamientos o procesos en el taller que repercuten directamente en la producción. Localizar y comprender estos puntos de datos, en otras palabras, puede traducirse directamente en una mayor productividad. En segundo lugar, los valores atípicos pueden perjudicar el rendimiento de muchos algoritmos de aprendizaje automático. Por lo tanto, determinar si necesitamos excluir estos puntos de nuestro análisis es fundamental para obtener información precisa.
Para determinar si nuestro conjunto de datos incluía valores atípicos, utilizamos un método llamado Bosque de aislamiento(puede leer más sobre esta técnica aquí).
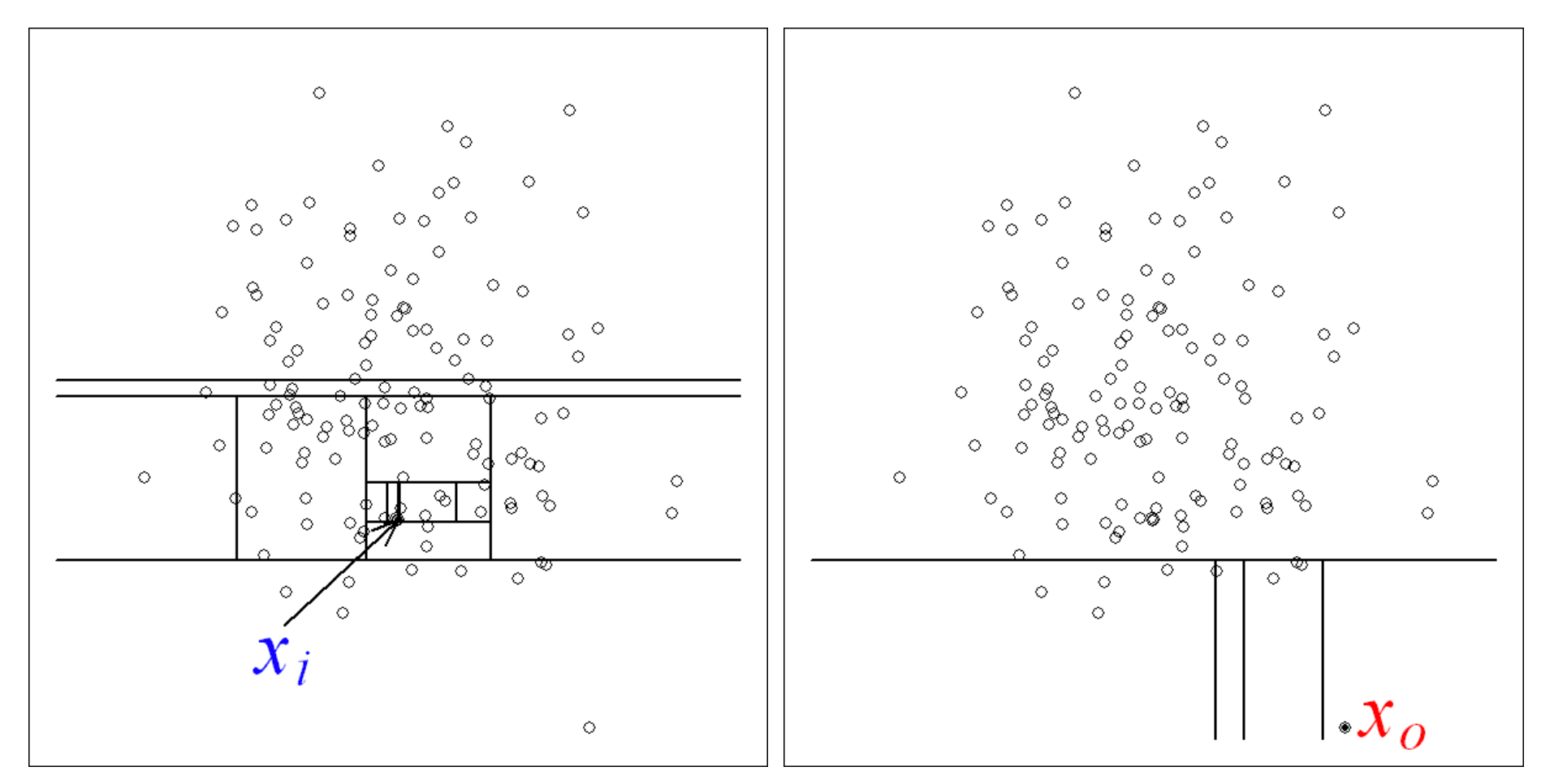
El bosque de aislamiento localizó 5 puntos de datos que consideró atípicos.
Esto no sólo nos proporciona un conjunto de datos más limpio, sino que nos permite formular una pregunta crítica: ¿qué ocurría con esas máquinas en esos momentos?
Graficar los valores atípicos en el tiempo para revelar las causas profundas
El último paso de este experimento consistió en volver a mapear nuestras anomalías en nuestro gráfico inicial del día de producción.
Observemos primero las tres líneas que se producen justo después de las 03:00. Si comparamos esto con nuestro gráfico inicial (velocidad de avance, velocidad del husillo, piezas producidas a lo largo del tiempo), vemos que estos tres valores atípicos coinciden con una caída precipitada de las tres métricas.
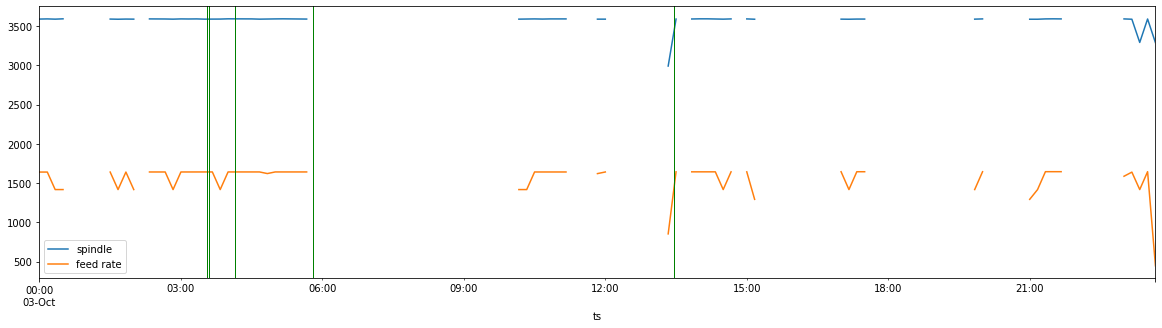
La pregunta es: ¿qué ocurrió entonces? Lo importante es que graficar estos sucesos de esta manera nos permite formular preguntas más informadas. ¿Quién era el operador? ¿Qué programa se estaba ejecutando? ¿Cuáles eran las condiciones de la fábrica? ¿Quién era el supervisor de turno? ¿Se realizó correctamente un cambio? ¿Se disponía de la herramienta adecuada? ¿Hubo algún problema mecánico?
Estas son algunas de las muchas preguntas que los fabricantes deben responder a diario para que sus operaciones sean lo más rentables posible.
Además, con la supervisión de máquinas de Tulip, no tiene por qué limitar su análisis a estas tres variables. Con Tulip, puede hacer un seguimiento de otros parámetros que añadirán matices y perspectiva a estos parámetros comunes.
Conclusiones
Este análisis es simplista. No hay razón para pretender lo contrario.
Pero si ejecuta sencillos análisis de aprendizaje automático sobre los datos de supervisión de su maquinaria, podrá determinar qué preguntas son las más adecuadas en cada momento.
Este es el verdadero valor de aumentar la supervisión de las máquinas con el aprendizaje automático. Los algoritmos pueden ayudarle a encontrar el orden en conjuntos de datos masivos. Pero, en última instancia, ofrecen a los ingenieros la oportunidad de aislar y resolver problemas de fabricación difíciles en menos tiempo y con más certeza que nunca.
Para concluir, hay un punto que nos gustaría destacar.
Pudimos elaborar este análisis en unas pocas horas. Como las tablas de Tulip recopilan y organizan los datos de forma accesible, no hubo necesidad de crear tablas con SQL y no tuvimos que dedicar mucho tiempo al minucioso trabajo de ingeniería de funciones.
Este tipo de análisis no requiere un máster en ciencia de datos ni software caro. Uno de nuestros ingenieros lo elaboró en unas horas utilizando bibliotecas de análisis estándar del sector y disponibles públicamente. Un equipo de analistas empresariales y científicos de datos que trabaje con conjuntos de datos personalizados recopilados por Tulip podría llegar mucho más lejos en el mismo tiempo.
Lo que pretendíamos aquí no era elaborar un análisis definitivo, sino mostrar lo fácil que es crear perspectivas que marquen la diferencia.
Póngase en contacto para empezar hoy mismo con la supervisión de máquinas.